数据产品基石 数据中台下的数仓模型架构与数据处理服务
在数据中台的建设体系中,数仓模型与架构是其坚实的数据基础,而数据处理服务则是驱动数据价值流动的核心引擎。本文将聚焦于数据中台的这两大支柱,阐述其设计理念与实践路径。
一、数仓模型:数据资产化的蓝图
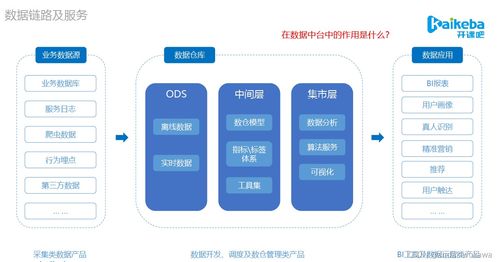
数仓模型是数据中台对原始数据进行有序组织和业务抽象的结果,是数据资产化的核心蓝图。它通常遵循分层设计思想:
- 贴源层(ODS):作为数据“湖泊”的入口,尽可能保留原始业务系统的数据全貌,实现数据的汇聚与初步清洗。
- 公共维度层(DIM)与明细层(DWD):此层是数据标准化的关键。通过定义一致的维度(如客户、产品、渠道)和对事实明细表进行清洗、关联、退化维度等操作,形成面向主题的、高质量的原子数据层,是数据复用的基础。
- 汇总层(DWS)与应用层(ADS):基于明细数据,按照业务分析需求进行轻度或重度汇总,形成可直接服务于报表、分析、推荐等具体场景的数据模型,提升数据使用效率。
一个良好的数仓模型,应具备稳定性、规范性、可扩展性,并能够清晰地映射业务过程,确保数据口径一致、血缘可追溯。
二、数仓架构:支撑大规模数据治理的骨架
现代数据中台下的数仓架构,已从传统的单一关系型数据库,演进为融合多种技术的复合型架构:
- 批流一体:结合Apache Hive、Spark等处理历史批量数据,同时利用Flink、Kafka等处理实时流数据,满足从T+1到秒级延迟的多样化需求。
- 湖仓一体:在低成本、高扩展的对象存储(数据湖)之上,构建具备数仓严格schema管理、ACID事务和优化性能的数据服务层,兼顾灵活性与规范性。
- 云原生与存算分离:基于云基础设施,实现存储与计算资源的独立弹性伸缩,降低运维成本,提升资源利用率。
这一架构的核心目标是实现数据的高效、稳定、低成本存储与计算,为上层服务提供可靠支撑。
三、数据处理服务:将数据资产转化为数据产品
数据处理服务是数据中台能力输出的窗口,它将底层的模型与数据,封装成易用、可靠、可复用的服务。主要包括:
- 数据开发与调度服务:提供可视化的ETL/ELT开发界面、任务依赖编排与自动化调度监控,降低数据开发门槛,保障数据处理流程的稳定运行。
- 数据API服务:将核心数据模型(如用户画像、商品标签)封装成标准的API接口,供前端应用、业务系统或分析工具实时调用,实现“数据随需而动”。
- 数据质量与治理服务:贯穿数据全生命周期,提供数据质量监控(完整性、准确性、一致性)、元数据管理、数据血缘追踪、数据安全脱敏等能力,确保数据可信、可用、可控。
- 实时计算与智能服务:提供实时指标计算、复杂事件处理(CEP)及集成机器学习平台的能力,支持实时推荐、风控预警等智能化场景。
###
数仓模型与架构定义了数据的“静态”组织形式,而数据处理服务则定义了数据的“动态”使用方式。二者相辅相成,共同构成了数据中台的核心能力。企业构建数据中台时,必须以业务价值为导向,设计贴合自身特点的模型与架构,并构建敏捷、高效的数据处理服务体系,方能将海量数据真正转化为驱动业务创新的核心资产,赋能前台的快速响应与创新。
如若转载,请注明出处:http://www.historyrl.com/product/6.html
更新时间:2026-03-31 17:49:46