哔哩哔哩数据服务中台建设实践 数据处理服务的核心架构与价值
在数字化浪潮的推动下,数据已成为互联网企业的核心资产。哔哩哔哩(Bilibili)作为中国领先的年轻人文化社区和视频平台,面对海量、多元、快速增长的业务数据,构建高效、稳定、可扩展的数据服务中台体系至关重要。其中,数据处理服务作为中台的核心组件,承担着从原始数据到业务价值的转化重任。本文旨在探讨哔哩哔哩在数据处理服务建设中的实践与思考。
一、 数据处理服务在中台体系中的定位
哔哩哔哩的数据服务中台旨在打破数据孤岛,提供统一、标准化的数据能力。数据处理服务位于数据采集与存储的下游,是数据应用与消费的上游。它主要负责数据的清洗、转换、集成、建模与加工,将原始日志和业务数据转化为主题明确、口径一致、易于使用的数据资产(如数据仓库分层表、数据模型、指标标签等),为数据分析、推荐系统、用户画像、业务监控等场景提供高质量的“数据燃料”。
二、 核心架构与技术选型
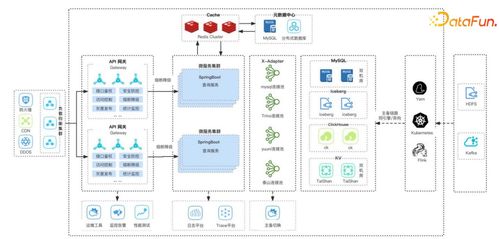
哔哩哔哩的数据处理服务构建在混合云环境之上,其核心架构遵循分层与解耦的设计原则:
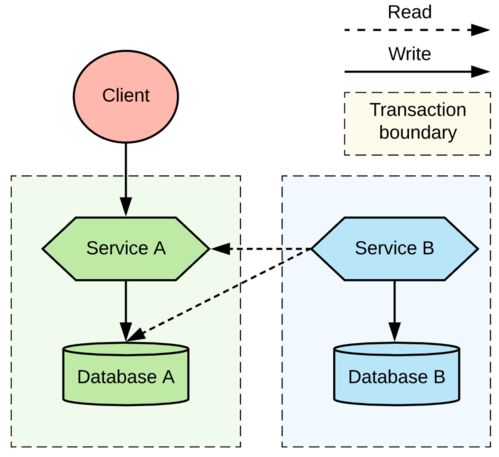
- 调度层:采用开源的分布式调度系统(如Apache DolphinScheduler或Airflow),负责管理和调度成千上万个数据处理任务。通过可视化的DAG(有向无环图)定义任务依赖关系,确保数据处理流程的有序、高效与容错。
- 计算引擎层:根据不同的数据处理场景,灵活选用多种计算引擎:
- 离线批处理:以Apache Spark为核心,处理TB/PB级别的历史数据,进行复杂的ETL(抽取、转换、加载)和聚合分析,支撑数据仓库的T+1数据更新。
- 实时流处理:采用Apache Flink作为实时计算引擎,对消息队列(如Kafka)中的流式数据进行实时清洗、统计与关联,实现秒级或分钟级的指标计算,满足实时推荐、风控和运营监控的需求。
- 交互式查询:引入Presto/Trino等引擎,提供对海量数据的亚秒级到秒级的即席查询能力,支持数据探查与自助分析。
- 存储层:数据仓库采用经典的层次建模(如ODS、DWD、DWS、ADS),使用HDFS、Hive、Iceberg/Hudi等存储格式,保障数据的一致性、可追溯性与高效访问。实时结果数据则可能存入在线数据库(如MySQL、ClickHouse)或缓存系统以供应用快速调用。
- 元数据与数据治理层:这是保障数据质量与效率的关键。建设统一的元数据中心,对数据血缘、资产目录、数据质量、任务链路进行全景监控与管理。通过数据质量稽核规则、任务SLA监控、资源成本优化等手段,确保数据处理服务的稳定、可靠与经济性。
三、 关键实践与挑战应对
- 任务治理与性能优化:面对数万计的日常任务,通过任务画像分析、资源动态分配、Spark/Flink参数调优、小文件合并、数据倾斜处理等手段,持续提升整体计算效率,降低集群成本。
- 数据质量保障:建立贯穿全链路的数据质量监控体系。在关键任务节点设置数据完整性、准确性、一致性校验规则,实现异常自动告警与熔断,避免“垃圾数据”污染下游应用。
- 敏捷数据开发:为数据开发人员提供一站式的开发平台,集成任务开发、调试、测试、发布与运维功能,降低技术门槛,提升数据产出的迭代速度。
- 应对业务高速增长:哔哩哔哩业务场景多样(视频、直播、电商、社区等),且数据量增长迅猛。数据处理服务通过架构的弹性伸缩能力、计算存储分离、以及向云原生架构(如Kubernetes)的演进,来支撑业务的快速变化与规模扩张。
四、 价值与展望
通过建设强大的数据处理服务,哔哩哔哩数据中台实现了:
- 效率提升:数据产出时间从天级缩短到分钟级,数据需求响应速度大幅加快。
- 成本可控:通过资源优化与精细化治理,在数据量指数增长的让单位计算成本得到有效控制。
- 质量可靠:统一、标准、高质量的数据资产,增强了各业务方对数据的信任度,驱动数据驱动决策的文化落地。
- 赋能创新:为A/B测试、个性化推荐、智能运营等深度应用提供了坚实的数据基础,直接赋能业务增长与用户体验优化。
哔哩哔哩的数据处理服务将继续向智能化、自动化和服务化的方向发展。例如,探索AI for DataOps,实现任务异常的智能诊断与自愈;深化实时数仓能力,推动流批一体技术的全面落地;并进一步将数据处理能力以API或数据服务的形式更便捷地开放给业务方,让数据价值的释放更加高效与直接。数据处理服务作为数据价值链的“锻造车间”,其持续演进将是哔哩哔哩在数据时代保持竞争力的重要基石。
如若转载,请注明出处:http://www.historyrl.com/product/21.html
更新时间:2026-04-06 04:55:36